厌氧消化是一个包含多个生物转化和物理化学转化的复杂过程,特别是产甲烷菌对环境条件要求比较苛刻.为了消除厌氧消化过程中多种干扰的影响及保持厌氧消化过程稳定、高效的进行,就需要对厌氧消化过程进行合适的监测和控制,而大量大型沼气工程的建立更是加剧了这种需求.针对传统物化参数(pH值、温度、产气量和氧化还原电位等)已有成熟的在线测量设备,而对厌氧消化过程有重要影响的物化参数,如挥发性脂肪酸(VFA,Volatile Fatty Acids)和生理参数(如生物量)却难以实现在线测量.
VFA是厌氧消化的中间产物也是产甲烷的主要底物,与pH值、碱度、产气量和气体组分等常规指标相比,VFA更能快速可靠地指示厌氧消化系统的状态.在工业厌氧消化产甲烷反应器运行中,经常发生因为未及时发现VFA的积累使pH下降至3~5而导致的“酸败”.“酸败”的发生对厌氧反应器往往是灾难性的,反应器一旦发生“酸败”,很难在短时间内恢复或者根本难以恢复反应器内产甲烷微生物的活性,因此,对VFA浓度的检测方法一直受到高度的重视.目前,VFA浓度离线测定的方法主要有蒸馏法、滴定法、色谱法、比色法等,然而离线分析耗时、滞后,不能满足快速变化的高负荷厌氧消化系统的在线监测需求.为了实现VFA的在线监测,研究人员也进行了大量研究.例如,Feitkenhauer等(2002)设计了一个基于滴定计的VFA在线测量系统,其主要特点是设备简单成本低,缺点是检测的只是总挥发酸;Zhang等(2002)研究的红外光谱能针对乙酸、丙酸等进行测量,但其准确性和灵敏度欠佳;Diamantis等(2006)和Boe等(2007)分别设计了带自动取样器的毛细管气相色谱、顶空气相色谱,其与反应器的连接实现了VFA的在线精确测量,但气相色谱昂贵,难以实现工业化应用;赵全保(2008)设计的在线测定VFA和碱度的自动滴定系统只是实现了滴定过程的自动化,并未将计算模型与计算机集成,所构建的6点滴定法滴定准确,但操作繁琐、计算复杂.可靠又便宜的VFA在线监测设备已经成为制约厌氧消化技术应用与发展的瓶颈,而上述VFA在线监测技术仍然处于实验室阶段,并未应用到实际工业中,因此,有必要进一步研究VFA的在线监测技术.
一般解决工业过程的测量问题有两条途径:一是沿袭传统的检测技术思路,以硬件形式实现过程参数的直接在线测量(如上所述);另一种就是采用间接测量的思路,利用容易获取的其他测量信息,通过计算来实现对被测变量的估计.近年来,在过程控制和检测领域涌现出的软测量的技术就是这一思想的集中体现.软测量理论根源是20世纪70年代Brosilow提出的推断控制,所谓软测量就是根据可测、易测的过程变量(即辅助变量)与难以直接获取的待测变量(即主导变量)的数学关系,按照某种最优准则,采用各种计算方法,用软件手段实现对待测变量的测量或估计.因此,软测量技术又称为软仪表技术,目前己经在过程控制与优化中得到了广泛的应用.
软测量技术一般来说主要包含:辅助变量选取、数据预处理、软测量建模和模型校正4个部分.辅助变量的选择一般没有通用性的指导方法,常根据具体对象通过理论和经验分析,选取与主导变量相关的变量作为辅助变量.辅助变量选取过多会使后续建模较为复杂,而减少辅助变量可能丢失部分信息降低模型精度.主成分分析是统计学中用于降低高维数样本最直接的手段之一,同时还尽最大的可能保持原有样本的所有信息,从而被广泛应用.软测量技术的主体和核心是建立软测量模型,建立模型的常规方法主要有:机理建模法、回归分析法、神经网络法和支持向量机方法等.其中,神经网络和SVM这两种同属黑箱建模方法,不要求对象的确定内部机理,因此,比较适合复杂的污水处理过程,应用亦最为广泛.Dixon等(2007a)在一篇数据挖掘的文章中用神经网络以进水流速、厌氧反应器内pH值、沼气产量、甲烷产量和二氧化碳产量等5个变量为输入变量对出水VFA进行预测,结果表明,神经网络模型能够较好的预测出水VFA值,但神经网络是一种局部最优算法,易过拟合且对于神经网络隐含层数和隐含层节点数的选择并无理论上的指导.姚崇龄等(2006)提出了一种基于减法聚类的神经模糊网络软测量建模方法来预测VFA的值,仿真结果表明,该方法具有很好的拟合精度和预测精度,但模糊神经网络需要大量的数据来确定模型参数,对于数据量较少的样本并不适用.SVM是近年来在机器学习领域中受到关注较多的一种基于统计学原理的新技术,相比神经网络的启发式学习机制,SVM的经验成分甚少,具有更为严格的数学论证.同时,SVM对于所提供的样本数据的依赖性较少,且泛化能力较强,局部最优解一定是全局最优解,避免了产生维数灾难.在SVM基础上Suykens提出了最小二乘法支持向量机,主要是将最小二乘线性系统引入到SVM中,用训练误差的二次平方项e2代替优化目标中的松弛变量,并用等式约束代替不等式约束,最终将问题归结为求解一线性方程组,大大减少了运行时间,提高了训练的速度.针对厌氧废水处理系统出水VFA难以在线监测的问题,本文提出一种基于PCA-LSSVM的软测量建模方法,通过 Matlab2013a 软件平台建立模型,以期为厌氧出水VFA的在线监控和厌氧废水处理系统优化控制提供指导.
2 材料与方法(Materials and methods) 2.1 辅助变量的初步确定
出水VFA浓度能反映厌氧反应器内VFA的积累状况,而VFA在厌氧反应器内的积累能反映出产甲烷菌的不活跃状态或反应器操作条件的恶化,因此,出水VFA是厌氧反应器运行状态的重要指标.影响厌氧反应器运行状态的因素一般也会影响出水VFA浓度,废水的厌氧生物处理受到许多因素的影响,常分为环境因素和工艺操作条件两大类.环境因素是影响厌氧废水生物处理过程的根本条件,主要包括温度、pH值、氧化还原电位、碱度及包括生物可降解性、营养元素、微量元素和毒性等在内的废水水质特征等.工艺操作条件主要包括厌氧反应器类型、预处理方式、水力停留时间、有机负荷和污泥负荷等.实验采用IC厌氧反应器处理人工葡萄糖配水,故不需考虑废水水质特征、厌氧反应器类型、预处理方式的影响.有机负荷和污泥负荷会随着水力停留时间的改变而改变,所以三者仅考虑水力停留时间.沼气是厌氧消化的气相产物,主要包括CH4、CO2和少量H2.沼气产量及其组分分布直接反映了厌氧反应器的运行状况和反应器内的微生物活性,因此,沼气产量及其组分分布与出水VFA浓度有一定相关性.
根据传感器的可用性、可靠性和价格,Dixon将用来测量厌氧消化过程的传感器分为4个级别.根据Dixon的分级,本文对厌氧消化过程的传感器的种类进行扩充,扩充后的维恩图如图 1所示.在这些传感器中级别越低的越可靠且越便宜,从图中可以看出,VFA传感器属于第3个级别.软测量应使用较低级别或者同级别的传感器来预测该级别传感器的变量,否则软测量就失去了实际意义.综合以上两方面,辅助变量初步选择为温度、HRT、pH、ORP、沼气流量(Qgas)、CH4、CO2、H2含量等8个变量.
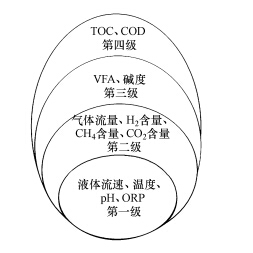
图 1 厌氧消化过程传感器级别的维恩图
2.2 实验装置
实验装置为实验室搭建的厌氧废水处理系统,实验装置示意图如图 2所示.实验所用的IC厌氧反应器为有机玻璃制作,高1272 mm,内径200 mm,有效容积25.1 L,第一反应区与第二反应区的体积比为4 ∶ 1.通过BT600-2J型蠕动泵控制废水和饱和NaHCO3的进水流量,从而控制废水停留时间和反应器内的pH值.在线监测系统由在线监测仪表、数据传输转换模块(ADAM4017+、ADAM4024、ADAM4520)、工控机(TPC1521H)及其监控组态软件(通用版MCGS 6.2)组成,其中,在线监测仪表包括在线pH仪表(美国哈希公司,GLI MODEL33)、在线ORP仪表(GOLDTO TP560)、PT100温度传感器(u2p-010)和电远传湿式气体流量计(LML-1型).
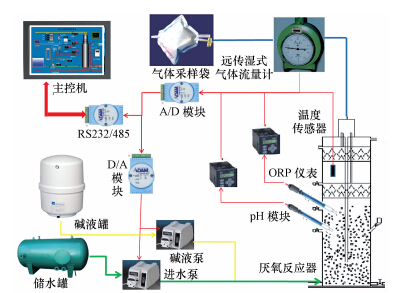
图 2 实验装置示意图
2.3 实验方法
实验用水为人工有机废水,用葡萄糖、尿素、磷酸二氢钾按COD ∶ N ∶ P=200 ∶ 5 ∶ 1 的比例配制COD为3000 mg ・ L-1左右的废水,同时加入1.8 mg ・ L-1 CaCl2・2H2O、0.5 mg ・ L-1 MgSO4、0.25 mg ・ L-1 CuSO4・5H2O、0.248 mg ・ L-1 CoCl2・6H2O、0.24 mg ・ L-1 FeCl3・5H2O、0.205 mg ・ L-1 ZnCl2、0.19 mg ・ L-1 NiCl2・6H2O、0.014 mg ・ L-1 H3BO4和0.009 mg ・ L-1 NH4MoO4・4H2O,以保证厌氧微生物微量元素所需.IC厌氧反应器的接种污泥取自广州南沙某造纸厂的IC厌氧反应器,接种污泥的VSS浓度为23.78 g ・ L-1,TSS浓度为35.56 g ・ L-1.污泥接种前先进行筛洗处理,再用COD为3000 mg ・ L-1的葡萄糖废水持续48 h漂洗和活化.IC厌氧反应器外有保温泡沫但无加热装置,整个运行过程在室温下进行. 启动前期维持HRT为24 h,相应容积负荷为3 kg ・ m-3 ・ d-1(以COD计),当COD去除率达80%且产气稳定时,通过提高进水流量控制HRT为15.36、12.29、9.83 h,通过调节饱和NaHCO3溶液的流量控制反应器内的pH值在6.5~7.2之间.在每个水力停留时间运行稳定后开始采集稳定运行数据,干扰数据则通过降低进水碱度使反应器酸化来获取.实验期间,pH值、 ORP、温度和沼气流量采用上述仪表在线监测;出水COD采用重铬酸钾滴定法测量,每日1次;沼气气体组分采用气相色谱(A90气相色谱仪)校正因子归一法测量,每8 h 1次;出水VFA浓度采用气相色谱(A90气相色谱仪)外标法测定,每8 h取样测量1次.
2.4 PCA原理步骤
1)首先通过公式(1)计算原始数据矩阵 X m×n的均值和方差,然后利用公式(2)对 X m×n进行零均值标准化处理得到标准化矩阵Z m×n:
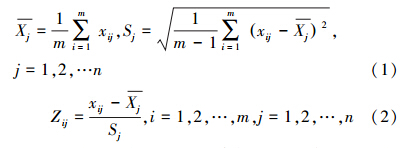
2)利用公式(3)和(4)求标准化矩阵 Z m×n的协方差矩阵 R n×n:
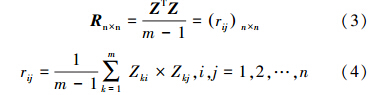
3)根据公式(5)解出 R 的n个特征值λj(j=1,2,…,n),并按从大到小的顺序排列,λ1≥λ2≥…≥λn≥0,根据公式(6)求解相应特征值的单位特征向量 b j(j=1,2,…,n),b j=(b1j,b2j,…,bnj):
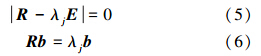
4)按公式(7)计算累计方差贡献率,确定主成分个数k,累计方差贡献率≥85%的前k个主成分包含了绝大部分信息,后面的其他成分可以舍弃:
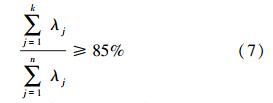
5)利用公式(8)将标准化矩阵 Z 在k维上投影,组成k个主元的新的数据样本矩阵 U,U1称为第一主成分,U2称为第二主成分…Uk称为第k主成分,这样原始数据样本实现了从n维到k维:
2.5 LSSVM
对于给定样本集 D {(xi,yi),i=1,2,…,l},其中,xi∈ R n为n维输入向量,yi∈ R 为目标输出,LSSVM可描述为如下优化问题:
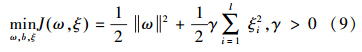
引入Lagrange函数:
式中,αi是Lagrange乘子,利用Karush-Kuhn-Tucker′s(KKT)最优化条件对上式进行优化,对ω、b、ξ、α求偏导可得:
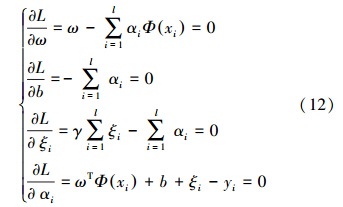
消除ω、ξ,优化的问题就可以转化为下面的线性方程求解问题:

式中,定义K(xi,xj)为核函数,常用的核函数有线性核函数、多项式核函数、径向基核函数(RBF)和Sigmoid核函数.文中采用径向基核函数RBF建立软测量模型,该核函数形式为:
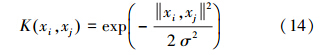
式中,σ为核宽度,令Ω= Ωij|i,j=1,2,…,l ,I= 1,1,…,1 T,α= α1,α2,…,αlT,y= y1,y2,…,yl T,则上式可以化简为:
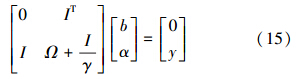
利用最小二乘法解上述线性方程组可求得α与b的估计,则估计所得的软测量模型为:
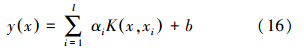
3 PCA-LSSVM在线软测量模型的建立(Online soft-sensing model based on PCA-LSSVM)
整个PCA-LSSVM软测量流程如图 3所示.
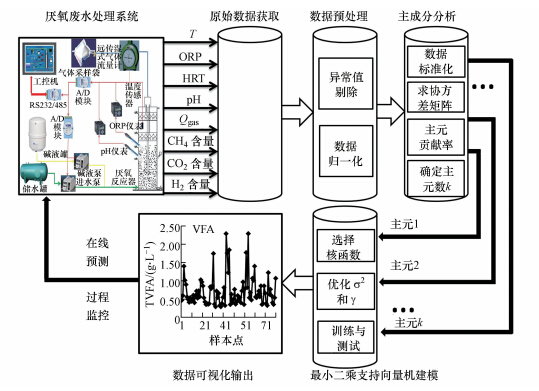
图 3 PCA-LSSVM软测量流程图
3.1 原始数据采集及预处理
采用颗粒污泥接种,厌氧反应器可以快速启动.厌氧废水处理系统稳定运行后开始采集数据,按照实验方法连续运行120 d.稳态采集到的数据人工剔除明显异常值后利用拉依达准则剔除离群值,然后从中选取90组数据作为稳态数据,其中,前70组作为训练数据,后20组作为测试数据.为了验证模型对厌氧反应器酸化条件的预测性能及LSSVM模型的抗干扰和泛化能力,降低进水碱度使反应器酸化并采集酸化条件下的非稳态数据,并从中选取30组加入稳态数据组成稳态干扰数据,前85组作训练数据,后35组作预测数据.数据选择好以后,分别对稳态数据和稳态干扰数据进行归一化处理以消除量纲影响.稳态干扰数据的任意两个参数的二维图如图 4所示,可以从整体上看出数据的特点,如ORP 多数集中在-500~-400 mV之间,温度集中在20~30 ℃之间,产气量在0~2 L ・ h-1之间等,并且在某些散点图中更容易识别数据尖峰.
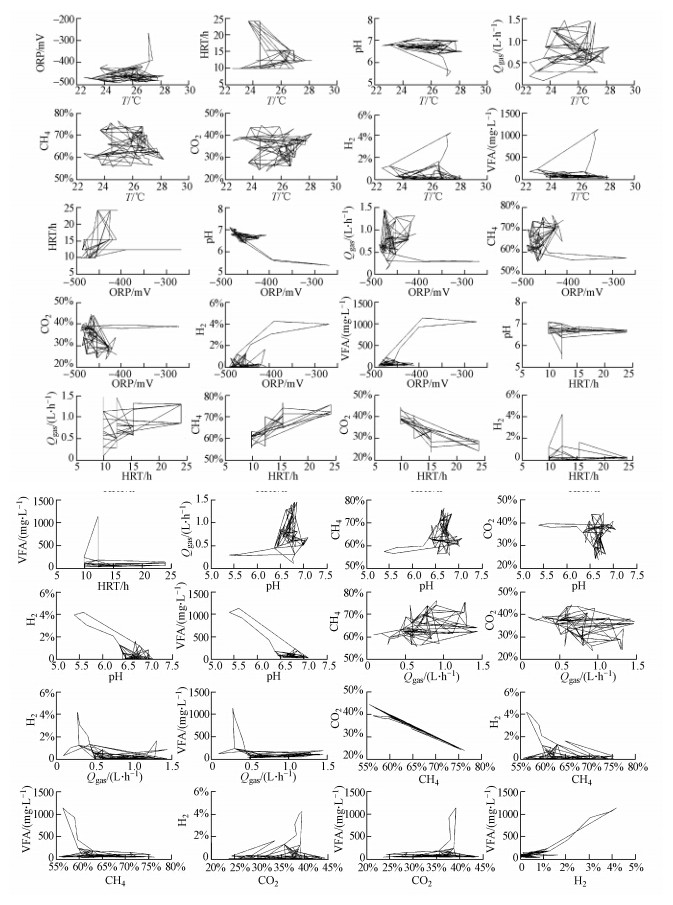
图 4 稳态干扰数据多变量二维散点图
3.2 主成分分析
为了去除冗余信息及减少LSSVM的计算量,对预处理后的数据使用MATLAB 2013a软件进行PCA分析各个变量的相关性同时降低输入数据维数.图 5为稳态数据和稳态干扰数据的2-D双标图,双标图显示了辅助变量与样本点之间的多元关系.对于稳态数据,第一主成分的方差贡献率为46.22%,第二主成分的方差贡献率为15.03%,合起来总贡献率为61.25%,属于中等稍偏好的拟合度水平. 前两个主成分的IR值均大于1(表 1,分别为3.24和1.05),表明稳态数据的2-D双标图可以很好地表现数据中的规律.对于稳态干扰数据,第一主成分的方差贡献率为49.11%,第二主成分的方差贡献率为22.19%,合起来总贡献率为71.30%,也属于中等稍偏好的拟合度水平.稳态干扰数据的前两个主成分的IR值分别为3.43和1.55,均大于1,因此,稳态干扰数据的2-D双标图也可以很好地表现数据中的规律.
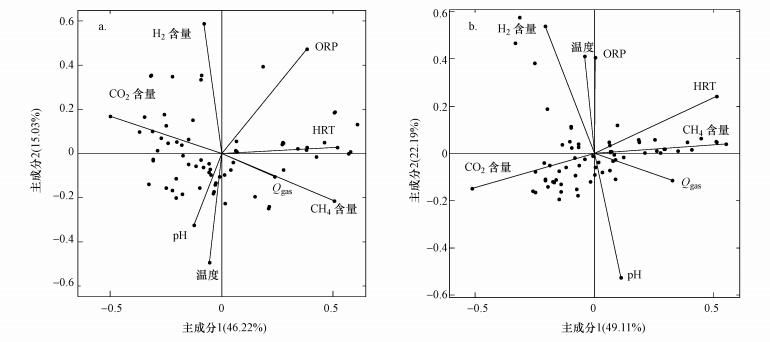
图 5 稳态数据(a)和稳态干扰数据(b)的双标图
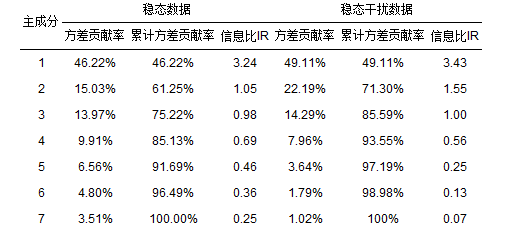
表 1 各主成分方差贡献率、累计方差贡献率及信息比
双标图中连接原点和各变量的直线称为“向量”,向量在某一主成分上的投影表明该变量对该主成分的重要程度,同时也体现了该主成分对该变量的解释程度.两变量向量间夹角近似表明了两个变量的相关关系,夹角小于90°表示正相关,大于90°表示负相关,接近90°表示不相关.图中的点代表原始数据在第一主成分和第二主成分的量化观测值.从变量之间的夹角来看,无论是稳态干扰数据还是稳态数据CO2含量与HRT、CH4含量和产气量Qgas,以及pH值与H2含量和ORP都呈显著负相关,但负相关程度有所变化,如稳态数据的CO2含量与CH4含量和Qgas夹角接近180°,而稳态干扰数据CO2含量与CH4含量和产气量Qgas夹角减小,与HRT的夹角接近180°.对于pH值与温度的相关性,稳态数据与稳态干扰数据却呈现截然相反的相关性,即稳态数据pH值与温度正相关.而稳态干扰数据pH值与温度是负相关,这可能是因为稳态干扰数据中包含了部分酸化数据,尽管此时温度可能较高但由于酸化pH值仍然较小.从变量的矢量长度来看,CH4含量、CO2含量、H2含量与HRT都是重要的影响变量,温度和产气量Qgas都是不太重要的变量.在稳态数据中ORP较pH值重要,但在稳态干扰数据中pH值比ORP更为重要,这可能是因为稳态干扰数据中pH值的变化比ORP更明显.
从表 1可以看出,对于稳态数据,前4个主成分的累计方差贡献率为85.13%,前5个主成分的累计方差贡献率达91.69%;对于稳态干扰数据,前3个主成分的累计方差贡献率为85.59%,前4个主成分的累计方差贡献率则达到93.55%.综合考虑,对于稳态数据选择前5个主成分作为LSSVM模型的输入变量,对于稳态干扰数据选择前4个主成分作为LSSVM模型的输入变量.
建模时,为了得到较好的性能,需要选择合适的核函数、核参数 sig2和正则化参数 gam.本文选取径向基函数(RBF)作为 LSSVM 的核函数,应用Matlab2013a软件,使用LSSVM工具箱并编写程序,采用网格搜索法确定核参数sig2和gam最优范围,然后用10倍交叉验证法最终选出稳态数据LSSVM模型最优 sig2 =0.04187,gam =41.475,稳态干扰数据LSSVM模型的sig2 =0.30875,gam =162.206.
模型预测性能指标包括以下几个:①相对误差(Relative Error,RE),RE 表示绝对误差值与被测量值的真实值之比,相对误差更能反映预测的可靠程度;②平均绝对百分比误差(Mean Absolute Percent Error,MAPE),MAPE是所有相对误差的绝对值求和的平均值,能从整体上更好地反映预测值的实际情况;③均方根误差(Root Mean Square Error,RMSE),RMSE主要是为了说明样本的离散程度.RMSE的值越小,说明预测模型描述实验数据具有更好的精确程度,反之,模型预测精度较差;④相关系数(correlation coefficient,r),r反映了预测值与实际值线性关系的强弱,r越接近于1则预测值与实际值越接近.各指标具体计算公式如下:
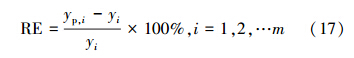
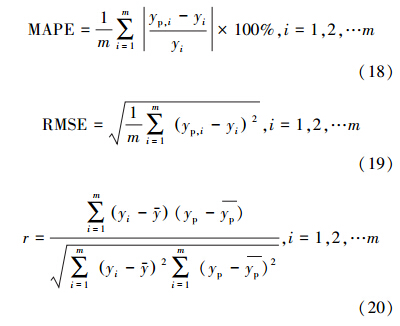
式中, 为实际值均值,yp 为预测值均值,m为样本数目.
4 结果与讨论(Results and discussion) 4.1 稳态LSSVM模型仿真结果
稳态LSSVM的仿真结果见图 6~8及表 2.由图 6~8及表 2可知,在训练过程中稳态LSSVM模型的最大相对误差为7.67%,平均相对百分比误差为1.75%,均方根误差为1.36;在测试数据中模型的最大相对误差为4.72%,平均相对百分比误差为1.61%,均方根误差为1.08,整体预测数据与实际数据的相关系数达0.9996.由上可以看出,稳态LSSVM模型对稳态条件下厌氧废水处理系统出水VFA具有很好的仿真预测能力.

图 6 稳态LSSVM模型对VFA预测结果
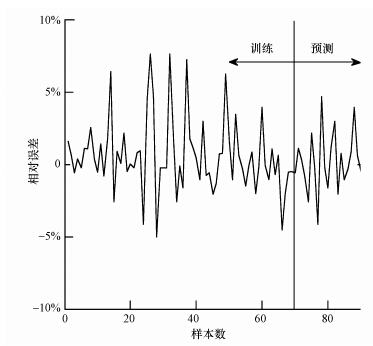
图 7 稳态LSSVM模型的训练和测试相对误差
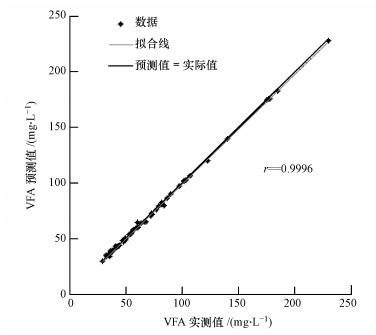
图 8 稳态LSSVM模型的相关系数
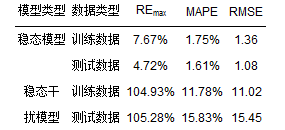
表 2 稳态模型与稳态干扰模型LSSVM的预测性能
4.2 稳态干扰LSSVM模型仿真结果
稳态干扰LSSVM的仿真结果见图 9~11及表 2.由图 9来看,稳态干扰LSSVM模型基本上可以预测系统的稳态干扰变化.具体来看模型的性能指标可以发现,在训练过程中稳态干扰LSSVM模型的最大相对误差为104.93%,在测试过程中模型的最大相对误差为105.28%,二者与稳态下的模型性能相比可以说大了1个数量级,这在很大程度上是因为稳态干扰数据中添加了部分厌氧废水处理系统酸化条件下的数据.酸化条件下的数据相对于稳态下的数据来说可以算是异常数据,这使得稳态干扰数据中VFA的最大值也几乎提升了1个数量级.稳态干扰LSSVM模型的训练过程与测试过程平均相对百分比误差分别为11.78%和15.83%,相对于稳态LSSVM模型相对误差百分比来说偏大,但考虑到数据变化幅度的增大,这一点还是可以接受的.与平均相对误差百分比相似,稳态干扰模型的均方根误差也相应幅度的变大,训练和测试的均方根误差分别为11.02和15.45.与上述3个性能指标不同,模型的预测值与实际值仍然具有较高的相关系数(0.9984),这也在一定程度上说明上述3个性能指标的下降可能是少量酸化数据造成的.从最大相对误差、平均相对百分比误差和均方根误差的角度来看,稳态干扰LSSVM模型性能有大幅度下降不足以预测稳态干扰变化下厌氧系统出水VFA的浓度,但考虑到数据幅度的变化及模型整体预测性能,稳态干扰LSSVM模型还是能够预测出水VFA浓度波动的,因此,仅用一个指标来评价模型的性能是不合适的,若要更为精确地预测出水VFA浓度波动,可能需要更多酸化数据来训练模型.
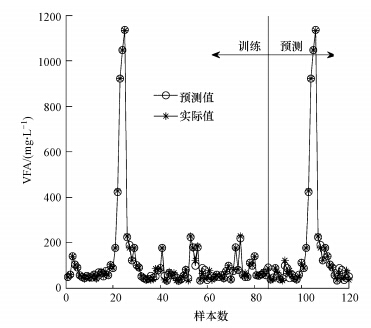
图 9 稳态干扰LSSVM模型对的VFA预测结果
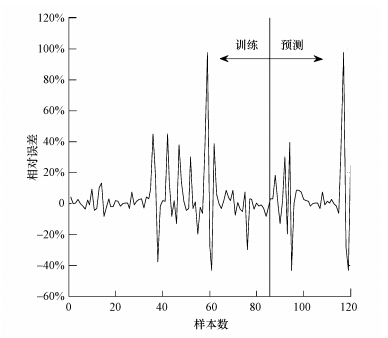
图 10 稳态干扰LSSVM模型的训练和测试相对误差
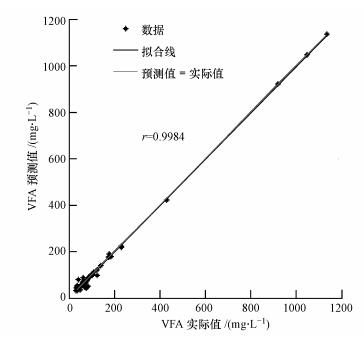
图 11 稳态干扰LSSVM模型的相关系数
5 结论(Conclusions)
1)PCA可以分析各变量与样本点之间的多元关系,同时有效实现输入变量降维,通过PCA处理稳态数据输入变量可以由8个降到5个,稳态干扰数据输入变量由8个降到4个,这有利于降低后续建模的复杂度,提高模型的计算速度.
具体参见污水宝商城资料或http://www.dowater.com更多相关技术文档。2)利用稳态数据建立的稳态LSSVM模型,对稳态条件下厌氧废水处理系统出水VFA具有很好的仿真预测能力,测试样本的最大相对误差为4.72%,平均相对百分比误差为1.61%,均方根误差为1.08,整体预测数据与实际数据的相关系数达0.9996.
3)利用稳态干扰数据建立的稳态干扰LSSVM模型,由于数据幅度变大,模型对厌氧废水处理系统出水VFA的仿真预测精度有所降低,测试过程中模型的最大相对误差达105.28%,平均相对百分比误差为15.83%,均方根误差为15.45,但整体上模型的预测值与实际值的相关系数仍然高达0.9984,这说明稳态干扰LSSVM模型对大幅度波动的厌氧废水处理系统仍然具有较好的预测能力.

