
申请日 2016.12.28
公开(公告)日 2017.04.26
IPC分类号 G06Q50/26; G06K9/62
摘要
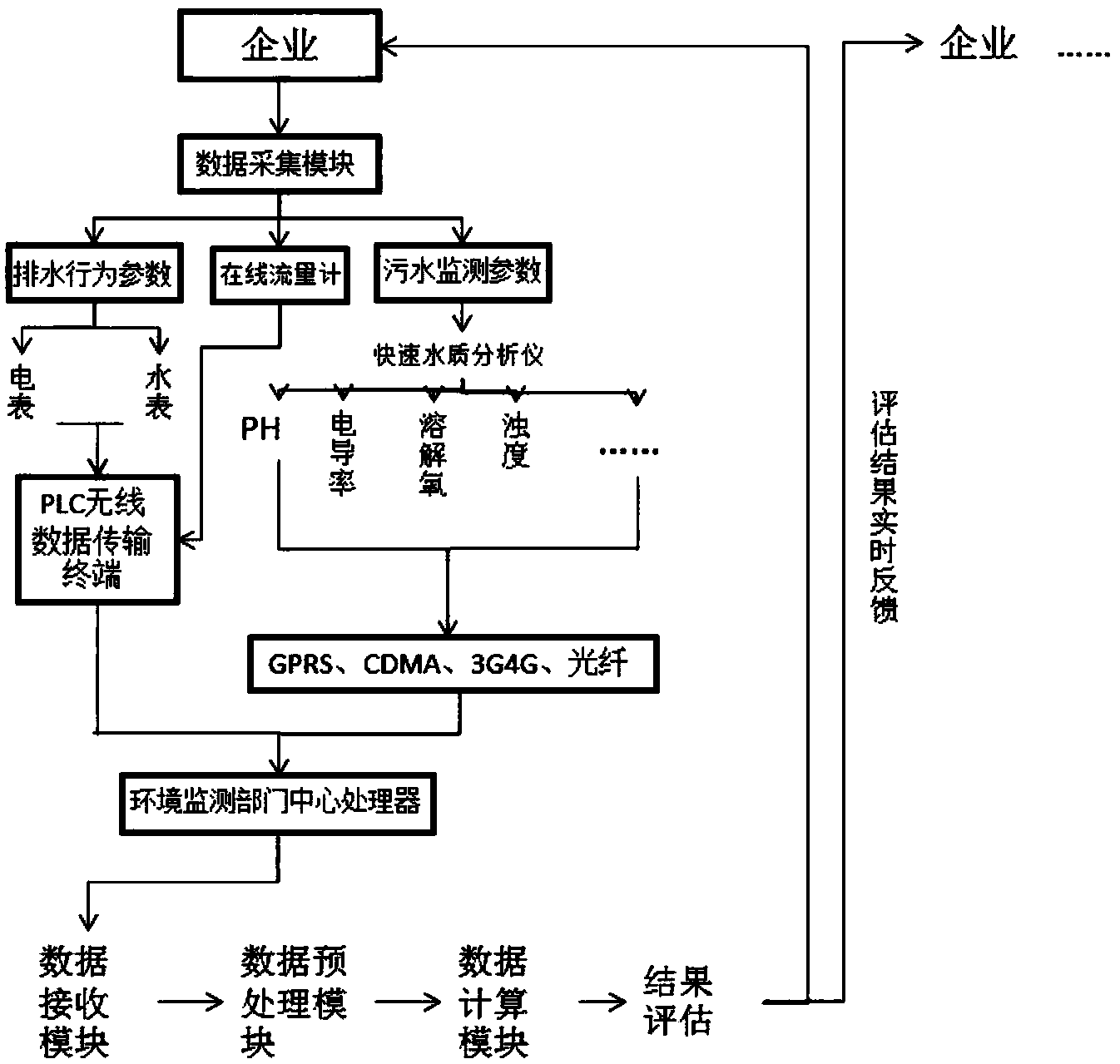
本发明公开了一种基于基础数据处理和分析的、实时且低成本的判断企业在污水处理过程中是否存在兑水排污行为的方法,算法部分包括:基于历史数据的线性网络训练判断企业的排水行为是否正常,基于多企业联合数据的聚类分析判断企业的污水处理行为是否正常,并设计了数据采集、数据传输、数据处理、运算结果反馈的系统流程,并根据企业的排水行为和污水处理行为设计了联合判定条件,以综合判断企业的污水处理工艺是否达标。
权利要求书
1.本发明基于企业关于污水排放的基础数据,以基础数据的线性网络训练和聚类分析为基础,从企业的排水行为和污水处理行为两个方面综合分析,构建以环境监测部门为数据处理中心、各个企业之间为终端的互联网络,快速处理分析各个监测周期末企业上传的数据,并将运算结果实时反馈给各个企业,督促企业做出相应调整,对不合格者实行停业整顿,实现对多家企业在线判断其是否存在兑水排污的行为。
2.本发明以基础数据的线性网络训练为基础判断企业的排水行为是否正常,基础数据及意义如下:
企业在一个监测周期内耗电总量W,单位KWh
企业在一个监测周期内耗水总量C,单位t
以上数据为企业日常生产的量化指标,无需成本即可获得,若企业不存在兑水排污的行为,两者必然以生产力的大小呈定量平衡;若存在兑水排污行为,则这种定量平衡会被打破,比如企业为了兑水偷排,关掉污水处理设备,引入自来水管排污,则相对的电量会减少,耗水总量会增多。本发明以大数据的线性网络训练的方式来挖掘此定量关系,并对企业今后的排水行为进行判断,具体操作如下:提取某企业三年来工作日内n个监测周期(规定每四个小时为一个监测周期,每个工作日提取三次数据)W、C数据压缩入n*3的输入矩阵,以零向量为输出矩阵,通过反解线性方程得出三者加权系数b,b为3行1列的列向量,将输入矩阵乘以b得到的结果是以0为均值的标准正态分布,将新的监测数据(第n+1组)作为新的输入数据乘以列向量b,根据正态分布3σ原则,得到的数值若落在大概率范围内,则可认为企业不存在兑水排污的现象,排水行为合格;若落在小概率范围内,则企业存在兑水排污的现象,排水行为不合格,样本空间越大,判断越准确,且不断加入的新监测数据会作为判断信息修正样本空间,数据储存在环境监测中心数据库。
。
3.本发明基于聚类分析的方法判断企业的污水处理行为是否正常,通过快速检 测代表水质污染情况的几项基础指标,对各个企业污水处理行为进行聚类分析,将聚类分析结果分为良好、一般、较差三个等级,本发明规定基础数据均采用高优指标,预处理过程对数据进行[0,1]规格化,并剔除波动较大的点,对聚类结果进行打分,测试参数及其意义如下:
(1)电导率:为衡量液体导电能力的指标,未经生化处理的污水中大多为悬浮颗粒物和有机大分子团,导电能力差,生化处理后离子浓度升高,导电能力明显增强,为高优指标,记为D,单位为S/m
(2)PH:对于特定的企业,由于其生产产品的特性和工艺特点致使其排放废水一般呈酸性或碱性,经生化处理后应稳定在中性左右,测量值记为E
(3)氧化还原电位:氧化还原电位反应液体的宏观氧化-还原性,氧化还原电位越高,液体电化学性越强,氧化还原电子对越多,说明液体生化处理的不彻底,取其测量值倒数转化成高优指标,记为
(4)水温:水温为衡量污水处理的指标之一,大多数的生化反应对温度具有一定需求,大约在35~45度左右,若进行兑水排污必然会降低水温。测量值记为T,为高优指标
(5)色度:纯净的水是无色的,泥沙、胶体、藻类的存在会影响水的色度,色度越大污染越严重,取其测量值倒数转化为高优指标,记为
(6)浊度:指水中悬浮物对光线透过时所发生的阻碍程度,水中的悬浮物一般是泥土、砂粒、微细的有机物和无机物、浮游生物、微生物和胶体物质等,浊度越大污染越严重。取其测量值倒数转化为高优指标,记为
(7)溶解氧:经生化处理后的污水溶解氧应呈明显上升的趋势,水中溶解氧低会促进滋生厌氧微生物,导致水体变质。测量值记为R,为高优指标
以上七个指标的快速检测手段目前已十分成熟,能够达到实时、廉价、高效的目的,且其参数本身又具备污水的绝大多数特征,形成特征空间作为聚类 分析特征空间的维度,聚类分析算法如下:
a、从样本空间中随机取3个元素,作为3个簇的各自的中心;
b、分别计算剩下的元素到3个簇中心的相异度(欧式距离),将这些元素分别划归到相异度最低的簇;
c、根据聚类结果,重新计算3个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数;
d、将样本空间中全部元素按照新的中心重新聚类;
e、重复第4步,直到聚类结果收敛;
f、将结果输出;
聚类分析为无监督的机器学习,聚类过程的依据就是每个样本的不同维度上的特异值,在本发明中则代表着企业对污水处理的不同效果:经过严密生化处理的污水很显然与兑水排污的污水有差别,根据其差别将各个企业污水处理结果分为三个等级:
良好:经过严格生化处理
一般:经过较好的生化处理
较差:生化处理不严格
聚类分析的结果作为对企业今后生化处理行为的判断,再对系统输入新的数据时系统会根据其特征自动进行分类,即达到了快捷、实时的在线监测效果。
说明书
一种基于基础数据分析判断企业兑水排污行为的方法
技术领域
本发明专利应用于环境保护领域,是基于基础数据分析的方式判断企业是否存在兑水排污行为的方法
技术背景
我国是一个水资源短缺、水旱灾害频繁的国家。人均水资源排名非常靠后,2015年我国人均水资源世界排名第102,人均水资源2173立方米,仅为世界平均水平(6055立方米)的三分之一,是人均水资源最贫乏的国家之一,且有下降的趋势,目前已从2010年的2310立方米/人下降至2015年的2173立方米/人。
我国的水质情况也不容乐观,2015年十大流域水质IV类~V类累计占比达30%,水污染非常严重。从水质变化趋势来看,近年来虽稍有下降的趋势,但污染总量仍十分惊人。造成水污染的原因有很多,废水的大量排放是最主要的原因。废水按来源的不同可以分为三类:工业废水、生活污水、农业污水。其中工业废水是水域的重要污染源,其有流量大、面积广、成分复杂、毒性大、不易净化、难处理等特点。近年来,我国污水排放总量持续增长,1998~2013年我国污水排放量由395亿吨上升至695亿吨,复合增长率为3.84%。从可持续发展角度来看,污水处理刻不容缓。
生活污水的处理属于公共事业,主要由政府主导建设,而工业废水的处理对企业来说则是一项成本,由政府强制要求,因此必须有国家政策的强力引导才能有效实行。国家制订了一系列政策包括环境整体规划、污水处理率规划、污水排放标准规定、国家监管政策等。
企业的污水处理一般为物理方法和生物化学方法相结合,其中物理方法通过物理作用分离、回收废水中不溶解的呈悬浮状态的污染物(包括油膜和油珠)的废水处理法,操作较为简单,周期短。生物化学方法主要通过生化方法去除污水中有机物和无机盐,目前国内的污水生化处理尚不完善,大多数的企业还停留在“废水靠看”的阶段,凭经验来处理污水,为保障水体水质和用水安全,我国已出台了一系列法规和条例。2015年4月,国务院正式发布了《水污染防治行动计划》,简称“水十条”,其中之一就是全面控制污染物排放。截止年底,全国已建成344个省级、地市级监控中心,在15559家重点污染源安装了自动监控设 备,大幅度提高了环境监管能力,向建设具有我国特色的自动化、信息化的环境监管体系迈出了重要一步。然而自动监控设备也存在着一些弊端,就是不能避免某些中小型企业为了降低处理成本,因而存在的兑水排污的行为。稀释后的污水虽然在污染物浓度表征上达到了要求,但污染物总量并没有变,有害物质随着生态循环进入环境仍会造成恶劣影响,治标不治本。污水水质鉴定周期长,工作量大,实现多企业联网、快速实时的在线监测难度很大。本发明不需要搭载复杂且高成本的硬件平台,从企业的基础数据入手,降低成本且高效快速。
发明内容
1.本发明基于企业关于污水排放的基础数据,以基础数据的线性网络训练和聚类分析为基础,从企业的排水行为和污水处理行为两个方面综合分析,构建以环境监测部门为数据处理中心、各个企业之间为终端的互联网络,快速处理分析各个监测周期末企业上传的数据,并将运算结果实时反馈给各个企业,督促企业做出相应调整,对不合格者实行停业整顿,实现对多家企业在线判断其是否存在兑水排污的行为。
2.本发明以基础数据的线性网络训练为基础判断企业的排水行为是否正常,基础数据及意义如下:
企业在一个监测周期内耗电总量W,单位KWh
企业在一个监测周期内耗水总量C,单位t
以上数据为企业日常生产的量化指标,无需成本即可获得,若企业不存在兑水排污的行为,两者必然以生产力的大小呈定量平衡;若存在兑水排污行为,则这种定量平衡会被打破,比如企业为了兑水偷排,关掉污水处理设备,引入自来水管排污,则相对的电量会减少,耗水总量会增多。本发明以大数据的线性网络训练的方式来挖掘此定量关系,并对企业今后的排水行为进行判断,具体操作如下:提取某企业三年来工作日内n个监测周期(规定每四个小时为一个监测周期,每个工作日提取三次数据)W、C数据压缩入n*3的输入矩阵,以零向量为输出矩阵,通过反解线性方程得出三者加权系数b,b为3行1列的列向量,将输入矩阵乘以b得到的结果是以0为均值的标准正态分布,将新的监测数据(第n+1组)作为新的输入数据乘以列向量b,根据正态分布3σ原则,得到的数值若落在大概率范围内,则可认为企业不存 在兑水排污的现象,排水行为合格;若落在小概率范围内,则企业存在兑水排污的现象,排水行为不合格,样本空间越大,判断越准确,且不断加入的新监测数据会作为判断信息修正样本空间,数据储存在环境监测部门数据库。
3.本发明基于聚类分析的方法判断企业的污水处理行为是否正常,通过快速检测代表水质污染情况的几项基础指标,对各个企业污水处理行为进行聚类分析,将聚类分析结果分为良好、一般、较差三个等级,本发明规定基础数据均采用高优指标,预处理过程对数据进行[0,1]规格化,并剔除波动较大的点,对聚类结果进行打分,测试参数及其意义如下:
(1)电导率:为衡量液体导电能力的指标,未经生化处理的污水中大多为悬浮颗粒物和有机大分子团,导电能力差,生化处理后离子浓度升高,导电能力明显增强,为高优指标,记为D,单位为S/m
(2)PH:对于特定的企业,由于其生产产品的特性和工艺特点致使其排放废水一般呈酸性或碱性,经生化处理后应稳定在中性左右,测量值记为E
(3)氧化还原电位:氧化还原电位反应液体的宏观氧化-还原性,氧化还原电位越高,液体电化学性越强,氧化还原电子对越多,说明液体生化处理的不彻底,取其测量值倒数转化成高优指标,记为
(4)水温:水温为衡量污水处理的指标之一,大多数的生化反应对温度具有一定需求,大约在35~45度左右,若进行兑水排污必然会降低水温。测量值记为T,为高优指标
(5)色度:纯净的水是无色的,泥沙、胶体、藻类的存在会影响水的色度,色度越大污染越严重,取其测量值倒数转化为高优指标,记为
(6)浊度:指水中悬浮物对光线透过时所发生的阻碍程度,水中的悬浮 物一般是泥土、砂粒、微细的有机物和无机物、浮游生物、微生物和胶体物质等,浊度越大污染越严重。取其测量值倒数转化为高优指标,记为
(7)溶解氧:经生化处理后的污水溶解氧应呈明显上升的趋势,水中溶解氧低会促进滋生厌氧微生物,导致水体变质。测量值记为R,为高优指标
以上七个指标的快速检测手段目前已十分成熟,能够达到实时、廉价、高效的目的,且其参数本身又具备污水的绝大多数特征,形成特征空间作为聚类分析特征空间的维度,聚类分析算法如下:
a、从样本空间中随机取3个元素,作为3个簇的各自的中心;
b、分别计算剩下的元素到3个簇中心的相异度(欧式距离),将这些元素分别划归到相异度最低的簇;
c、根据聚类结果,重新计算3个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数;
d、将样本空间中全部元素按照新的中心重新聚类;
e、重复第4步,直到聚类结果收敛;
f、将结果输出;
聚类分析为无监督的机器学习,聚类过程的依据就是每个样本的不同维度上的特异值,在本发明中则代表着企业对污水处理的不同效果:经过严密生化处理的污水很显然与兑水排污的污水有差别,根据其差别将各个企业污水处理结果分为三个等级:
良好:经过严格生化处理
一般:经过较好的生化处理
较差:生化处理不严格
聚类分析的结果作为对企业今后生化处理行为的判断,再对系统输入新的数据时系统会根据其特征自动进行分类,即达到了快捷、实时的在线监测效果。





