
申请日2018.09.04
公开(公告)日2018.12.14
IPC分类号G05B13/04
摘要
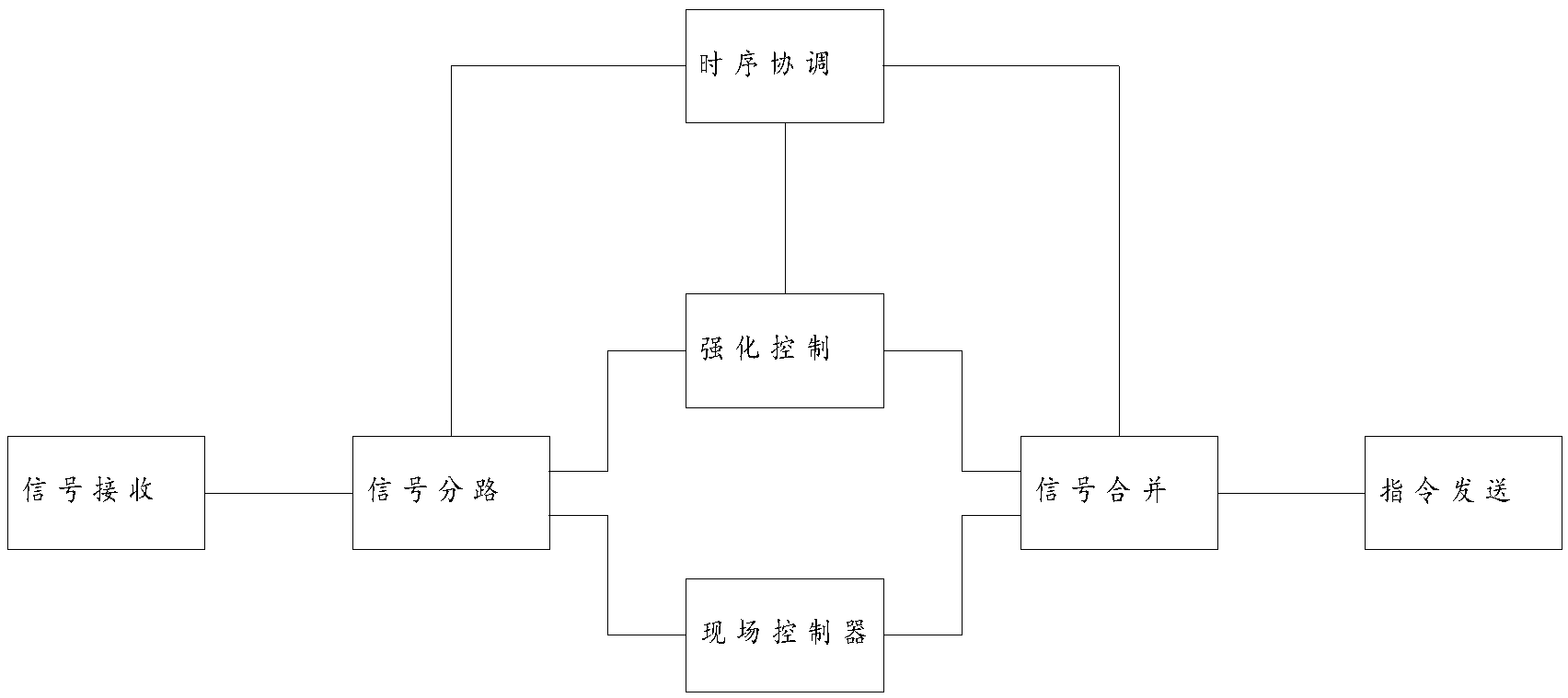
本发明提供了一种污水处理的强化学习控制方法;在现场控制器控制的过程中,获取现场控制器的输入信号,并将现场控制器的输出指令和强化学习模型的输出指令合并为最终输出指令输出控制,其中强化学习模型的输出指令中数值在最终输出指令总数值的占比为N,N从0逐渐增大至100%。本发明通过渐进比例提高强化学习模型控制权的方式,能有效在将强化学习模型的数据收集过程、训练学习过程放在实际场景中,而避免原始数据积累和虚拟环境搭建的过程,从而有效降低企业在应用强化学习的方式进行自动控制时所需的成本,方便用户完成从传统控制倒强化学习控制的过程。
权利要求书
1.一种污水处理的强化学习控制方法,其特征在于:在现场控制器控制的过程中,获取现场控制器的输入信号,并将现场控制器的输出指令和强化学习模型的输出指令合并为最终输出指令输出控制,其中强化学习模型的输出指令中数值在最终输出指令总数值的占比为N,N从0逐渐增大至100%;当强化学习模型的输出指令中数值在最终输出指令总数值的占比为100%时,切断现场控制器控制的输入和输出。
2.如权利要求1所述的污水处理的强化学习控制方法,其特征在于:所述将现场控制器的输出指令和强化学习模型的输出指令合并为最终输出指令输出,采用如下步骤:
a.获取现场控制器的输出指令和强化学习模型的输出指令;
b.将现场控制器的输出指令和强化学习模型的输出指令中的数值取出为现场控制器输出指令数值和强化学习模型输出指令数值;
c.将强化学习模型输出指令数值乘以系数N后更新为新的强化学习模型输出指令数值;
d.将现场控制器输出指令数值乘以系数(1-N)后更新为新的现场控制器输出指令数值;
e.将新的现场控制器输出指令数值和新的强化学习模型输出指令数值叠加得到输出指令叠加值;
f.将输出指令叠加值封装为输出指令发送指令。。
3.如权利要求1所述的污水处理的强化学习控制方法,其特征在于:所述N初始为0,每经过M次将现场控制器的输出指令和强化学习模型的输出指令合并为最终输出指令输出控制的步骤后,N自加0.5%。
4.如权利要求3所述的污水处理的强化学习控制方法,其特征在于:所述M取值由用户设定,但限定为5~20。
5.如权利要求1所述的污水 处理的强化学习控制方法,其特征在于:所述强化学习模型采用带值函数逼近的TD学习算法。
6.如权利要求1所述的污水处理的强化学习控制方法,其特征在于:所述强化学习模型的值函数为高斯核函数。
7.如权利要求1所述的污水处理的强化学习控制方法,其特征在于:所述强化学习模型采用如下方式更新:
a.获取现场控制器的输入作为当前现场控制器输入,将当前现场控制器输入作为值函数的输出反向计算值函数的输入,计算结果作为当前模拟输入;
b.根据当前模拟输入和前一现场控制器输入的误差值更新值函数,如无前一现场控制器输入,则将当前模拟输入直接作为误差值;
c.将当前现场控制器输入代入至更新后的值函数中计算输出指令值;
d.当前现场控制器输入更新至前一现场控制器输入,将输出指令值封装为输出指令发送,然后进入下一时序,等待获取现场控制器的输入。
8.如权利要求7所述的污水处理的强化学习控制方法,其特征在于:每一时序时长一小时。
说明书
一种污水处理的强化学习控制方法
技术领域
本发明涉及一种污水处理的强化学习控制方法。
背景技术
目前,强化学习在工业控制中的应用逐渐增多,但一般都限于特定的模型,其主要原因在于强化学习的训练需要环境支持,而在很多污水处理控制方面,完全模拟真实场景的环境所需要的计算量远远大于强化学习模型训练本身所需要的计算量,导致得不偿失,而且就目前的企业技术发展而言,原始的数据积累也很成问题。
发明内容
为解决上述技术问题,本发明提供了一种污水处理的强化学习控制方法,该污水处理的强化学习控制方法通过渐进比例提高强化学习模型控制权的方式,能有效在将强化学习模型的数据收集过程、训练学习过程放在实际场景中,而避免原始数据积累和虚拟环境搭建的过程。
本发明通过以下技术方案得以实现。
本发明提供的一种污水处理的强化学习控制方法;在现场控制器控制的过程中,获取现场控制器的输入信号,并将现场控制器的输出指令和强化学习模型的输出指令合并为最终输出指令输出控制,其中强化学习模型的输出指令中数值在最终输出指令总数值的占比为N,N从0逐渐增大至100%;当强化学习模型的输出指令中数值在最终输出指令总数值的占比为100%时,切断现场控制器控制的输入和输出。
所述将现场控制器的输出指令和强化学习模型的输出指令合并为最终输出指令输出,采用如下步骤:
a.获取现场控制器的输出指令和强化学习模型的输出指令;
b.将现场控制器的输出指令和强化学习模型的输出指令中的数值取出为现场控制器输出指令数值和强化学习模型输出指令数值;
c.将强化学习模型输出指令数值乘以系数N后更新为新的强化学习模型输出指令数值;
d.将现场控制器输出指令数值乘以系数(1-N)后更新为新的现场控制器输出指令数值;
e.将新的现场控制器输出指令数值和新的强化学习模型输出指令数值叠加得到输出指令叠加值;
f.将输出指令叠加值封装为输出指令发送指令。。
所述N初始为0,每经过M次将现场控制器的输出指令和强化学习模型的输出指令合并为最终输出指令输出控制的步骤后,N自加0.5%。
所述M取值由用户设定,但限定为5~20。
所述强化学习模型采用带值函数逼近的TD学习算法。
所述强化学习模型的值函数为高斯核函数。
所述强化学习模型采用如下方式更新:
a.获取现场控制器的输入作为当前现场控制器输入,将当前现场控制器输入作为值函数的输出反向计算值函数的输入,计算结果作为当前模拟输入;
b.根据当前模拟输入和前一现场控制器输入的误差值更新值函数,如无前一现场控制器输入,则将当前模拟输入直接作为误差值;
c.将当前现场控制器输入代入至更新后的值函数中计算输出指令值;
d.当前现场控制器输入更新至前一现场控制器输入,将输出指令值封装为输出指令发送,然后进入下一时序,等待获取现场控制器的输入。
每一时序时长一小时。
本发明的有益效果在于:通过渐进比例提高强化学习模型控制权的方式,能有效在将强化学习模型的数据收集过程、训练学习过程放在实际场景中,而避免原始数据积累和虚拟环境搭建的过程,从而有效降低企业在应用强化学习的方式进行自动控制时所需的成本,方便用户完成从传统控制倒强化学习控制的过程。





