
申请日2017.03.17
公开(公告)日2017.07.21
IPC分类号G06Q10/04; G06Q50/06
摘要
本发明为一种基于模糊神经网络预测污水水质数据的方法,包括以下步骤:收集训练和测试与系统所需要的样本;对所有训练样本进行聚类;对每条模糊规则对应的神经网络NNm进行训练,m代表模糊规则的个数,训练稳定后,将归一化后的关键水质指标作为预测样本输入模糊神经网络中进行对干粉投药量的预测。本发明的有益效果在于:企业就可以根据预测的水质数据,做到基于预测模型的泵站流量控制,以及确定污水处理时投放微生物、药剂的量和时间点,克服了传统的污水处理时凭经验判断泵站流量和添加药剂的人工操作,为污水的智能处理提供了强大的助力,具有良好的实际应用价值。
摘要附图
权利要求书
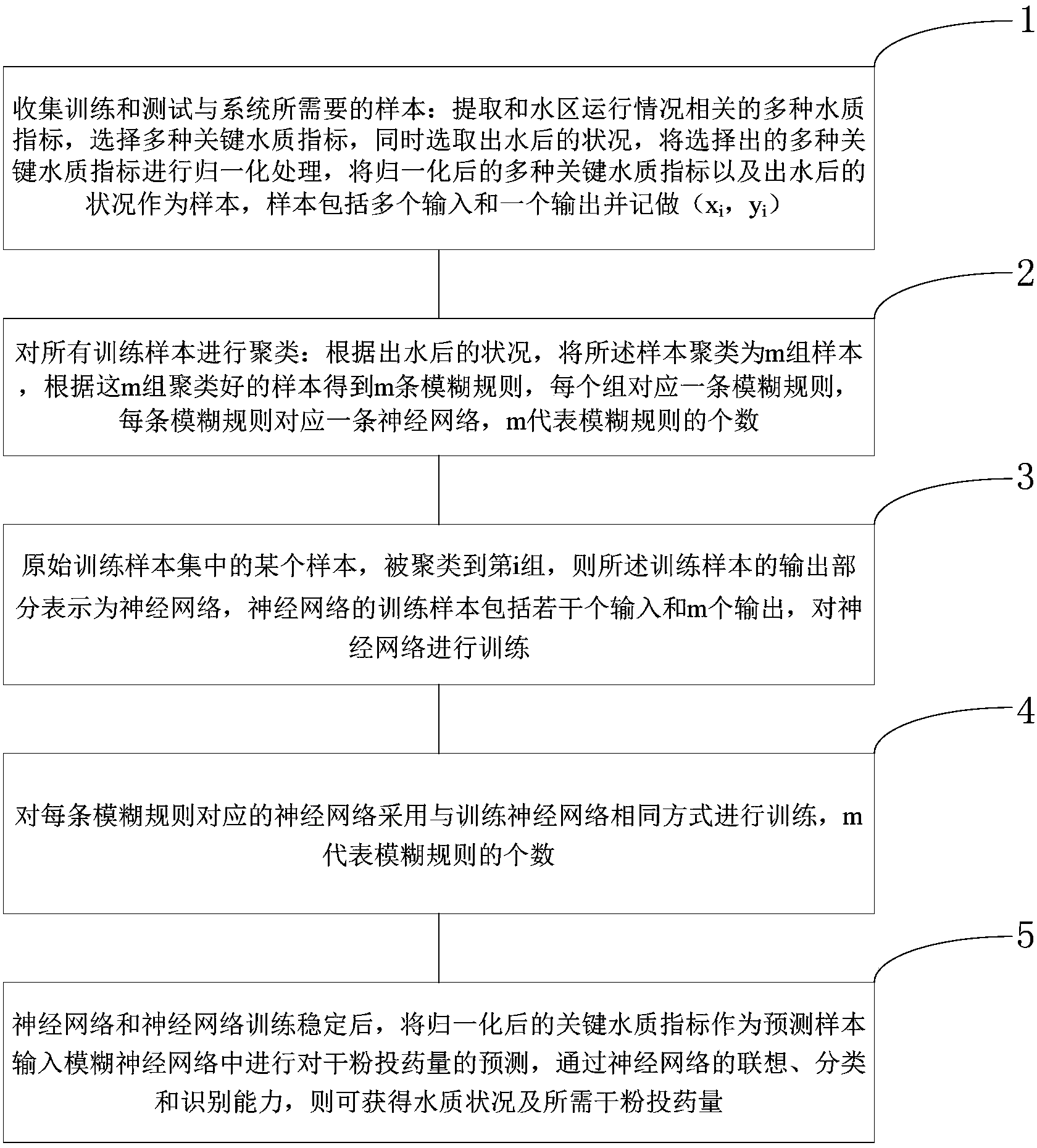
1.一种基于模糊神经网络预测污水水质数据的方法,其特征在于包括以下步骤:
收集训练和测试与系统所需要的样本:提取和水区运行情况相关的多种水质指标,选择多种关键水质指标,同时选取出水后的状况,将选择出的多种关键水质指标进行归一化处理,将归一化后的多种关键水质指标以及出水后的状况作为样本,样本包括多个输入和一个输出并记做(xi,yi);
对所有训练样本进行聚类:根据出水后的状况,将所述样本聚类为m组样本,根据这m组聚类好的样本得到m条模糊规则,每个组对应一条模糊规则,每条模糊规则对应一条神经网络NNm,m代表模糊规则的个数;
原始训练样本集中的某个样本,被聚类到第i组,则所述训练样本的输出部分表示为神经网络NNmf,表达式表示为式中j=1,…,m,神经网络NNmf的训练样本包括若干个输入和m个输出,对神经网络NNmf进行训练;
对每条模糊规则对应的神经网络NNm采用与训练神经网络NNmf相同方式进行训练,m代表模糊规则的个数;
神经网络NNmf和神经网络NNm训练稳定后,将归一化后的关键水质指标作为预测样本输入模糊神经网络中进行对干粉投药量的预测,通过神经网络的联想、分类和识别能力,则可获得水质状况及所需干粉投药量。
2.根据权利要求1所述的基于模糊神经网络预测污水水质数据的方法,其特征在于,所述对神经网络NNmf进行训练的具体过程为:
将所述训练样本中选取的关键水质指标进行归一化处理;
给出训练误差的允许值ε、β、μ0及权值和阈值所组成的向量x(k),当k=0时,x(0)为初始化权值和阈值组成的向量,k表示迭代次数;
当k=0,μ=μ0,得到网络输出及误差指标函数E(x(k));k表示迭代次数,μ表示比例系数;
计算雅可比矩阵J(x),计算公式如下:
根据雅可比矩阵J(x)得到公式Δx=-[JT(x)J(x)+μI]-1J(x)e(x),求得Δx,Δx是第k次迭代和第(k+1)次迭代的权重和阈值所组成的向量,JT(x)是J(x)矩阵的转置,μ表示比例系数,I表示单位矩阵,x表示水质指标;
若E(x(k))<ε,则停止训练;
当迭代次数为k+1时,以x(k+1)为权值和阈值组成的矩阵来计算E(x(k+1)),若E(x(k+1)) 3.根据权利要求2所述的基于模糊神经网络预测污水水质数据的方法,其特征在于,根据公式 , 求得Im的数值,nC是测试评价用的样本数,是m组内的样本数,是m组内对应xj的输出样本,xj表示输入,Im表示矩阵,μm表示隶属度,当Im的值在网络NNmf的训练中等于小于Δx时即可停止训练。 说明书 基于模糊神经网络预测污水水质数据的方法 技术领域 本发明涉及智能污水处理领域,具体涉及一种基于模糊神经网络的智能污水处理方法,融入了环境情景等因素。特别适用于污水处理厂根据水质变化确定干粉投药量。 技术背景 水是生命之源,它是人们赖以生存和发展的不可或缺的重要资源。但水资源是非常有限的,目前全世界的淡水资源仅占总水量的2.5%,而这些淡水资源中,近70%以两极冰盖和高山冰川的形式存在,难以被人们利用。我国水资源形势也不容乐观,人均水资源只有世界人均水平的四分之一,是世界人均水资源贫水国家之一。我国一方面严重缺水,另一方面因为生产工艺落后,水资源治理不善,乱排放污水,使得有限的水资源受到严重污染,这使得水资源环境雪上加霜。 在目前大多数的污水处理厂中,其智能控制系统仅具备数据采集与简单控制的功能,缺乏全局控制、系统优化与调整反馈模块;实际运行队伍中又相对缺乏高水平专业技术人员,生产中多以运行人员的经验为主导,海量监测数据未得到有效挖掘与应用,污水处理工艺调整时缺乏必要的科学量化依据。上述原因,导致现有污水处理厂智能控制系统能发挥的作用比较有限,仅作为“监控系统”,无法达到智能处理的要求。 水资源环境的数据存在以下的特征:1)在水资源系统中,污染物之间存在错综复杂的、难以确定的相关关系,进行综合评价时具有模糊性。2)根据水质的特点和环境指标来确定水质状况时,人为的因素较大,存在模糊性。3)水质变化是一个动态的过程,时常会忽略其的连续性,因而也存在模糊性。 针对水质数据的复杂性及模糊性,结合环境情景等因素,构建模糊神经网络(Fuzzy Neural Network,即FNN)的数学模型可以达到较优的智能控制效果及性能。人工神经网络(Artificial Neural Network,即ANN)是模仿人脑中的神经元网络,具备自学习能力和联系存储能力,人工干涉较少,精度较高,但缺点是它不能处理模糊信息,不能应用已有的知识经验。而模糊系统相对于神经网络而言,模糊系统的规则靠专家提供或设计,难以自动获取,但它对专家知识利用较好,推理过程容易理解。将这两者结合起来,起到了很多的互补效果,不仅具有自学习、联系、识别、自适应等功能,还能针对水质数据进行模糊信息处理。 发明内容 本发明的目的在于克服现有技术的不足之处,提出一种预测及评价污水处理厂生化水质特点并可以达到智能控制投药量的方法。 一种基于模糊神经网络预测污水水质数据的方法,包括以下步骤: 收集训练和测试与系统所需要的样本:提取和水区运行情况相关的多种水质指标,选择多种关键水质指标,同时选取出水后的状况,将选择出的多种关键水质指标进行归一化处理,将归一化后的多种关键水质指标以及出水后的状况作为样本,样本包括多个输入和一个输出并记做(xi,yi); 对所有训练样本进行聚类:根据出水后的状况,将所述样本聚类为m组样本,根据这m组聚类好的样本得到m条模糊规则,每个组对应一条模糊规则,每条模糊规则对应一条神经网络NNm,m代表模糊规则的个数; 原始训练样本集中的某个样本,被聚类到第i组,则所述训练样本的输出部分表示为神经网络NNmf,表达式表示为式中j=1,…,m,神经网络NNmf的训练样本包括若干个输入和m个输出,对神经网络NNmf进行训练; 对每条模糊规则对应的神经网络NNm采用与训练神经网络NNmf相同方式进行训练,m代表模糊规则的个数; 神经网络NNmf和神经网络NNm训练稳定后,将归一化后的关键水质指标作为预测样本输入模糊神经网络中进行对干粉投药量的预测,通过神经网络的联想、分类和识别能力,则可获得水质状况及所需干粉投药量。 作为一种可实施方式,所述对神经网络NNmf进行训练的具体过程为: 将所述训练样本中选取的关键水质指标进行归一化处理; 给出训练误差的允许值ε、β、μ0及权值和阈值所组成的向量x(k),当k=0时,x(0)为初始化权值和阈值组成的向量,k表示迭代次数; 当k=0,μ=μ0,得到网络输出及误差指标函数E(x(k));k表示迭代次数,μ表示比例系数,I表示单位矩阵; 计算雅可比矩阵J(x),计算公式如下: 根据雅可比矩阵J(x)得到公式Δx=-[JT(x)J(x)+μI]-1J(x)e(x),求得Δx,Δx是第k次迭代和第(k+1)次迭代的权重和阈值所组成的向量,JT(x)是J(x)矩阵的转置,μ表示比例系数,x表示水质指标; 若E(x(k))<ε,则停止训练; 当迭代次数为k+1时,以x(k+1)为权值和阈值组成的矩阵来计算E(x(k+1)),若E(x(k+1)) 作为一种可实施方式,根据公式 , 求得Im的数值,nc是测试评价用的样本数,是m组内的样本数,是m组内对应xj的输出样本,xj表示输入,Im表示矩阵,μm表示隶属度,当Im的值在网络NNmf的训练中等于小于Δx时即可停止训练。 本发明的创新点:1)在污水处理中,污水厂并没有关注及深入挖掘诸如季节、天气、气温等环境因素对污水水质指标数据的定性和定量影响,在污水的处理环节中并没有融入环境情景因素;2)针对水质数据模糊的特性,应用模糊神经网络对关键水质指标进行模糊信息处理,系统达到了较优的效果,对水质监测及预测有着重要意义。 本发明的有益效果在于:企业就可以根据预测的水质数据,做到基于预测模型的泵站流量控制,以及确定污水处理时投放微生物、药剂的量和时间点,克服了传统的污水处理时凭经验判断泵站流量和添加药剂的人工操作,为污水的智能处理提供了强大的助力,具有良好的实际应用价值。





