
申请日2017.04.14
公开(公告)日2017.09.05
IPC分类号G01N33/18; G06N3/00; G06K9/62
摘要
本发明公开了一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法。为了提高模型的精确性和鲁棒性,该检测方法结合了粒子群算法和支持向量机。本发明的软测量方法解决了测量设备滞后时间长的问题,真正实现对废水出水水质全面实时的监测,防止突发污染事故,同时可用于反馈控制实现厌氧废水处理系统的优化控制,为监控、优化和理解厌氧消化过程提供指导,可用于代替部分价格昂贵的测量设备,节省维护费用,降低废水处理成本,容易在废水处理工程推广应用,具有很好的社会效益和经济效益。
权利要求书
1.一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,包括如下步骤:
(1)搭建厌氧废水处理系统,获取并收集输入量以及不同输入量条件下对应的厌氧反应器输出量的元数据;
(2)将得到的元数据分为训练集p训练={x;y}和测试集p测试={x’;y’},并将数据集p={xx’;y y’}做归一化处理;将训练集数据用于SVM-regression模型建模,得到训练集的模型输出量Y,根据模型输出量Y与训练集实际值y的相对误差,将训练集分成两个训练集,即训练集①和训练集②,也即p训练1={x1;y1}和p训练2={x2;y2},并标记训练集①和训练集②的元数据标签分别为1和-1;
(3)根据分类的训练集①和训练集②,利用SVM-classification模型将测试集分成两个对应的测试集,即测试集①和测试集②,也即p测试1={x’1;y’1}和p测试2={x’2;y’2},从而将元数据分为两组数据集,即数据集①和数据集②,也即p1={x1x’1;y1y’1}和p2={x2x’2;y2y’2};
(4)将得到的训练集①和训练集②分别利用SVM-regression模型进行处理,并分别用对应的测试集①和测试集②验证模型的有效性;当模型的精度达到设定要求,得到包含SVM-classification模型和SVM-regression模型的PSO-SVM的出水挥发性脂肪酸软测量模型;
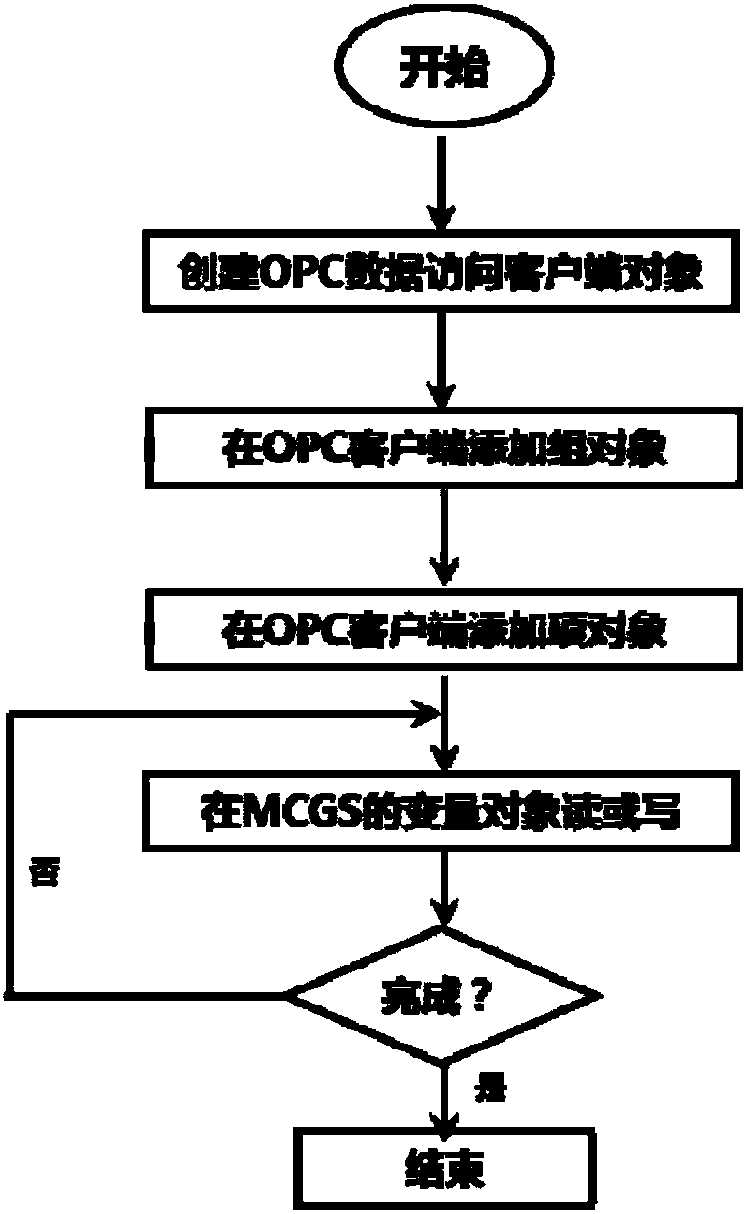
(5)将训练并测试后的PSO-SVM的出水挥发性脂肪酸软测量模型嵌入工控机中,并利用工控机中的组态软件构建好人机交互界面;
(6)采用OPC技术实现基于PSO-SVM的出水挥发性脂肪酸软测量模型与工控机的组态软件之间的数据交换,将收集的数据输送至PSO-SVM的出水挥发性脂肪酸软测量模型,计算出水挥发性脂肪酸浓度的预测值,再把该预测值返回至工控机人机交互界面显示;
(7)不断重复步骤(6),从而实现厌氧废水处理系统出水挥发性脂肪酸的在线实时监测;
(8)将系统输出以报表形式展现,并给出表征系统的表征指标指数。
2.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,步骤(1)中,所述厌氧废水处理系统包括厌氧反应器、与厌氧出水挥发性脂肪酸相关的监测和检测仪表、工控机、D/A及A/D模块;所述输入量包括进水有机负荷、出水pH、出水温度、产气的组分及产量、进水碱度和厌氧反应器的氧化还原电位;所述产气的组分及产量包括甲烷和二氧化碳的产量。
3.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,步骤(1)中,所述输出量包括出水总挥发性脂肪酸的浓度。
4.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,所述粒子群算法的粒子xj的速度及位置更新公式如下所示:
式中,Xj是粒子向量位置,Vj是粒子的速度,w是权重值,c1、c2为加速常数;rand1、rand2是随机函数,作用是为了产生(0,1)的随机数;pbest是个体极值,gbest是全局极值;k表示迭代次数;j表示向量维数。
5.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,步骤(2)中,所述归一化处理为:
式中,S(i)为数据集中的任一组数据;min(S)为数据集中,值最小的一组数据;max(S)为数据集中,值最大的一组数据。
6.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,步骤(2)中,模型输出量Y与训练集实际值y的相对误差低于50%的为训练集①;模型输出量Y与训练集实际值y的相对误差高于或等于50%的为训练集②。
7.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,步骤(3)中,所述SVM-classification模型为:
式中,x为辅助变量样本数据,为拉格朗日乘子,b*为偏移量,w*为最优权重值,T代表转置,xi*为最优样本数据,n为≥1的自然数;(xi,yj)为训练集样本,xn∈Rn,yn∈{-1,1}。
8.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,步骤(2)、(4)中,所述的SVM-regression模型为:
式中,x为辅助变量样本数据,ai为拉格朗日乘子,b为偏移量,n为≥1的自然数;k(xi,xj)为核函数且满足Mercer条件。
9.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,步骤(4)中,所述模型的精度要求由用户根据需要自行设置;步骤(8)中,所述表征指标指数包括相关系数、平均绝对百分比误差、相对误差和均方根误差。
10.根据权利要求1所述的一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,其特征在于,借助传输控制协议、互联网协议和串行数据标准,通过计算机和双向通信,对测量输出数据进行实时监控,并通过组态软件的监控窗口显示,从而系统及时、准确地了解污水处理系统的指标变化情况,促进污水处理厂高效稳定运行。
说明书
一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法
技术领域
本发明涉及废水处理技术领域,具体涉及一种厌氧废水处理系统出水挥发性脂肪酸的软测量方法。
背景技术
随着我国经济发展和工业化进程的加快,我国的废水排放量逐年增加,水污染控制任重而道远。厌氧生物处理工艺具有动力消耗小、污泥产量少、对氮和磷的需要量低,可减少补充氮和磷营养的费用、厌氧消化可产生生物能等优点,使得厌氧生物处理在工业废水处理中越来越重要,运用也越来越广泛。然而,厌氧消化过程是一个极其复杂、非线性、极具不确定的生化过程。一方面,厌氧微生物对包括三氯苯酚等有毒有机物较为敏感,若对于有毒废水性质了解不足或操作不当,在严重情况下可能导致反应器运行条件的恶化;另一方面,厌氧生物处理的效果容易受到操作条件变化的扰动,厌氧微生物(特别是产甲烷菌)对环境条件要求比较苛刻。当进水负荷突然增高或水温、碱度过低时,水解酸化过程与甲烷化过程容易失衡,从而导致有机酸大量积累、厌氧甲烷化受到抑制甚至厌氧体系崩溃。
由于厌氧消化体系的复杂性和易受运行条件的扰动的特点,厌氧消化过程的监控和水质参数的分析对于保证厌氧生物处理工艺的稳定性、高效性极为重要。然而,我国大部分废水处理厂在处理废水过程中大多靠人工化验来确定这些参数,人工化验不仅费时费力,还耗费了大量化学品,增加了污染物的排放量,严重影响了废水处理工艺的控制效果。虽然,由于近年仪表技术的发展,出现了可以在线测量这些废水水质的分析仪表,但这些专用仪表在我国发展比较晚,通常选用国外产品;同时,专用仪表普遍存在价格昂贵、设备投资和运行维护成本高、检测滞后时间长、稳定性不好和重复性差等问题,从而降低了重要参数的控制品质,这使其应用受到了进一步的限制。
近年来,基于人工神经网络、数理统计学等的软测量技术在废水处理过程中的应用越来越广。软测量模型适用于非线性系统建模,可以应用快速并行处理算法从而大大提高辨识速度。用于系统建模的方法很简单,只需通过系统的输入和输出数据,使系统对于水质变化频繁的废水生物处理仍然具有比较好的精度。近些年来,科研工作者对软测量建模技术以及其运用的研究和实践,特别是最近一两年人工智能算法和在各领域的运用逐渐成为研究热点,通过软测量技术构建的软测量系统逐步可以用来代替传统硬件仪表,也可以与硬件仪表同时使用以确保测量的准确性。
支持向量机(Support Vector Machine,SVM)是近年来机器学习领域中受到关注较多的一种软测量建模新技术,SVM基于统计学原理,相比神经网络的启发式学习机制,SVM的经验成分甚少,具有更为严格的数学论证。同时,SVM对于所提供的样本数据的依赖性较少,且泛化能力较强,局部最优解一定是全局最优解,避免了产生维数灾难,特别适用于解决小样本、非线性、局部极小点等问题。目前,针对挥发性脂肪酸的检测,研究人员提出了很多方法,基于支持向量机的厌氧废水处理系统出水挥发性脂肪酸的软测量方法也有相关的文献及专利报道。如刘博等提出一种基于PCA-LSSVM的厌氧废水处理系统出水VFA在线预测模型,仿真结果表明在稳态环境下该模型具有很好的仿真能力(刘博,万金泉,黄明智等.基于PCA-LSSVM的厌氧废水处理系统出水VFA在线预测模型.[J].环境科学学报,35(6):1768-1778.)。然而,从这些文献中可知,元数据集加入非稳态数据后,模型在非稳态环境下的仿真表现会受到干扰。
发明内容
本发明的目的是提供一种废水厌氧处理系统出水挥发性脂肪酸(VFA)的软测量方法,为了提高模型的精确性和鲁棒性,该检测方法结合了粒子群算法和支持向量机。
粒子群算法(Particle Swarm Optimization,PSO)用于对模型参数的选优。
支持向量机(SVM)特别适用于解决小样本、非线性、局部极小点等问题,且训练速度快,并对加入的元数据集具有有效的分类策略;SVM模型是在统计学习理论的VC维理论和结构风险最小原理之上发展而来的一种新的智能算法,是由Corinna Cortes和Vapnik等人(Cortes C,Vapnik V.1995.Support-Vector networks[J].Machine Learning,20(3):273-297)首先提出来,其基本思想就是引入核函数的概念,将低维空间不可分的问题通过核函数映射到高维空间线性可分,在高维空间做分类或者回归处理。
SVM最初是学术界针对两个数据类别的分类问题提出来的,分类问题可数学表达为:对于样本集(xi,yi),i=1,2,...,n,xn∈Rn,yn∈{-1,1},构造分类面WX+b=0,该分类面能将两类样本无错误的分开,并且使两类之间的距离最大;W、X为n维向量,线性判别函数的一般形式为g(x)=Wx+b,同倍缩放W、b使其进行归一化处理,使离分类面最近的样本满足|g(x)|=1,那么两类所有样本都满足|g(x)|≥1,其中两类样本的分类间隔为2/||W||。
则SVM要解决的数学问题是:在满足式(3)的条件下,求式(4)的最小值:
yi(wTxi+b)-1≥0,i=1,2,3……n (3);
定义lagrange函数,其中,ai为lagrange系数,ai≥0;问题转化为对w和b求lagrange函数的最小值。
分别对w、b、ai求偏微分,当等于零时,得:
式(6)和式(3)构成把原问题转化为如下凸二次规划的对偶问题的约束条件:
原问题形成不等式约束下的二次函数机制问题,存在唯一最优解;若为最优解,则其中不为零的样本即为支持向量;因此,最优分类面的权系数向量是支持向量的线性组合;
b*由约束条件式(3)等于零时求解,由此求得的最优分类函数是:
最终,SVM求解回归性问题可描述为如下优化问题:
式(9)中,为第i个样本点的训练误差,为经验风险,衡量机器学习的复杂性;γ>0为惩罚因子,又称正则化参数,用以在训练中平衡机器学习的复杂性和经验风险;式(9)应满足约束条件:
yi=wTΦ(xi)+b+ξi,i=1,2,3,……,n (10);
式(10)中引入Lagrange函数:
式(11)中,ai是Lagrange乘子,利用Karush-Kuhn-Tucker’s(KKT)最优化条件对式(11)进行优化,对w、b、ξ、ai求偏导可得:
消除w、ξ,式(11)优化的问题就可以转化为下面的线性方程求解问题:
式(13)中,将k(xi,xj)定义为核函数,解方程(13)求得ξ、ai的值,获得的回归模型,表达为:
本发明采用径向基核函数(RBF,Radial Basis Functions)作为核函数,即:
由式(15)得到的分类器与传统RBF方法的重要区别是,每个基函数中心对应一个支持向量,输出权值一般由算法自动确定的,式中σ为核宽度。
粒子群算法(PSO)和支持向量机(SVM)二者结合实现厌氧废水处理系统挥发性脂肪酸的软测量,对厌氧废水处理系统的在线监测及后续工艺优化控制具有重要意义,同时对厌氧废水处理系统其他难以在线监测的指标具有指导意义。
为了实现本发明目的,本发明的技术方案如下。
一种基于粒子群算法和支持向量机的废水厌氧处理系统出水挥发性脂肪酸的软测量方法,包括如下步骤:
(1)搭建厌氧废水处理系统,获取并收集输入量以及不同输入量条件下对应的厌氧反应器输出量的元数据;
(2)将得到的元数据分为训练集p训练={x;y}和测试集和p测试={x’;y’},并将数据集p={x x’;y y’}做归一化处理;将训练集数据用于SVM-regression模型建模,得到训练集的模型输出量Y,根据模型输出量Y与训练集实际值y的相对误差,将训练集分成两个训练集,即训练集①和训练集②,也即p训练1={x1;y1}和p训练2={x2;y2},并标记训练集①和训练集②的元数据标签分别为1和-1;
(3)根据分类的训练集①和训练集②,利用SVM-classification模型将测试集分成两个对应的测试集,即测试集①和测试集②,也即p测试1={x’1;y’1}和p测试2={x’2;y’2},从而将元数据分为两组数据集,即数据集①和数据集②,也即p1={x1 x’1;y1 y’1}和p2={x2x’2;y2 y’2};
(4)将得到的训练集①和训练集②分别利用SVM-regression模型进行处理,并分别用对应的测试集①和测试集②验证模型的有效性;当模型的精度达到设定要求,得到包含SVM-classification模型和SVM-regression模型的PSO-SVM的出水挥发性脂肪酸软测量模型;
(5)将训练并测试后的PSO-SVM的出水挥发性脂肪酸软测量模型嵌入工控机中,并利用工控机中的组态软件构建好人机交互界面;
(6)采用OPC(OLE for Process Control)技术实现基于PSO-SVM的出水挥发性脂肪酸软测量模型与工控机的组态软件之间的数据交换,将收集的数据输送至PSO-SVM的出水挥发性脂肪酸软测量模型,计算出水挥发性脂肪酸浓度的预测值,再把该预测值返回至工控机人机交互界面显示;
(7)不断重复步骤(6),从而实现厌氧废水处理系统出水挥发性脂肪酸的在线实时监测;
(8)将系统输出以报表形式展现,并给出表征系统的表征指标指数。
进一步地,所述粒子群算法是迭代模式的算法,数学描述为:
设在一个n维搜索空间中,种群x={x1,x2,……,xN}是由N个粒子构成,其中第i个粒子所处的当前位置为x1={xi1,xi2,……,xin}T,速度为v1={vi1,vi2,……,vin}T,该粒子的个体极值表示为P1={Pi1,Pi2,……,Pin}T,整个种群的全局极值表示为Pg={Pg1,Pg2,……,Pgn}T,按照粒子不断寻优的原理,粒子群算法的粒子xj的速度及位置更新公式如下所示:
式中,Xj是粒子向量位置,Vj是粒子的速度,w是权重值,c1、c2为加速常数;rand1、rand2是随机函数,作用是为了产生(0,1)的随机数;pbest是个体极值,gbest是全局极值;k表示迭代次数;j表示向量维数。
进一步地,步骤(1)中,所述厌氧废水处理系统包括厌氧反应器、与厌氧出水挥发性脂肪酸相关的监测和检测仪表、工控机、D/A及A/D模块。
进一步地,步骤(1)中,所述输入量包括进水有机负荷(COD)、出水pH、出水温度(T)、产气的量及组分、进水碱度和厌氧反应器的氧化还原电位(ORP)。
更进一步地,步骤(1)中,所述产气的组分及产量包括甲烷和二氧化碳的产量。
进一步地,步骤(1)中,所述输出量包括出水总挥发性脂肪酸的浓度。
进一步地,步骤(2)中,所述归一化处理为:
式中,S(i)为数据集中的任一组数据;min(S)为数据集中,值最小的一组数据;max(S)为数据集中,值最大的一组数据。
进一步地,步骤(2)中,模型输出量Y与训练集实际值y的相对误差低于50%的为训练集①;模型输出量Y与训练集实际值y的相对误差高于或等于50%的为训练集②。
进一步地,步骤(3)中,所述SVM-classification模型为:
式中,x为辅助变量样本数据,为拉格朗日乘子,b*为偏移量,w*为最优权重值,T代表转置,xi*为最优样本数据,n为≥1的自然数;(xi,yj)为训练集样本,xn∈Rn,yn∈{-1,1}。
进一步地,步骤(2)、(4)中,所述的SVM-regression模型为:
式中,x为辅助变量样本数据,ai为拉格朗日乘子,b为偏移量,n为≥1的自然数;k(xi,xj)为核函数且满足Mercer条件。
进一步地,步骤(4)中,所述模型的精度要求由用户根据需要自行设置。
进一步地,步骤(8)中,所述表征指标指数包括相关系数(R)、平均绝对百分比误差(MAPE)、相对误差(RE)和均方根误差(MSRE)。
表征指标指数的数学表达如下:
相关系数(correlation coefficient,R)反映了预测值与实际值线性关系的强弱,R越接近于1,则预测值与实际值越接近。
平均绝对百分比误差(Mean Absolute Percent Error,MAPE)是所有相对误差的绝对值求和的平均值,能从整体上更好地反映预测值的实际情况;
相对误差(Relative Error,RE)表示绝对误差值与被测量值的真实值之比,相对误差更能反映预测的可靠程度;
均方根误差(Root Mean Square Error,RMSE),观测值与真值偏差的平方与观测次数n比值的平方根,RMSE主要是为了说明样本的离散程度。
RMSE的值越小,说明预测模型描述实验数据具有更好的精确程度,反之,模型预测精度较差;
以上R、MAPE、RE、RMSE式中,y为实际值,y*为实际值均值,yp为预测值,为实际值均值,m为样本数量。
进一步地,借助传输控制协议、互联网协议和串行数据标准,通过计算机和双向通信,对测量输出数据进行实时监控,并通过组态软件的监控窗口显示,从而系统及时、准确地了解污水处理系统的指标变化情况,促进污水处理厂高效稳定运行。
与现有技术相比,本发明具有如下优点和有益效果:
(1)本发明提供了新的建模方法,引入分类策略来处理数据量大的对模型造成的性能下降问题,根据实验应用于实际,具备较好的仿真能力,可用于废水厌氧处理过程中出水VFA浓度的实时检测;
(2)本发明的建模方法对厌氧出水挥发性脂肪酸预测值与真实数据符合得较好,误差相对也较小,完全满足实际应用;
(3)本发明的软测量方法解决了测量设备滞后时间长的问题,真正实现对废水出水水质全面实时的监测,防止突发污染事故,同时可用于反馈控制实现厌氧废水处理系统的优化控制,为监控、优化和理解厌氧消化过程提供指导;
(4)本发明可用于代替部分价格昂贵的测量设备,节省维护费用,降低废水处理成本,容易在废水处理工程推广应用,具有很好的社会效益和经济效益。





