
申请日2018.08.08
公开(公告)日2019.01.04
IPC分类号G16C20/70; G16C10/00; G06K9/62
摘要
本发明公开了一种基于模糊聚类的支持向量回归算法,对污水中溶解氧DO的含量进行预测,针对污水处理过程中溶解氧实时测量难的问题,本方法首先通过模糊聚类把整个样本分成多个子样本,再在每个子样本上建立支持向量回归模型,然后进行集成,对污水中溶解氧DO的含量进行在线预测。该方法具有较高的预测精度,在综合性能上优于其它时间序列预测方法,为快速,准确预测水质提供了一种有效的解决方案。
权利要求书
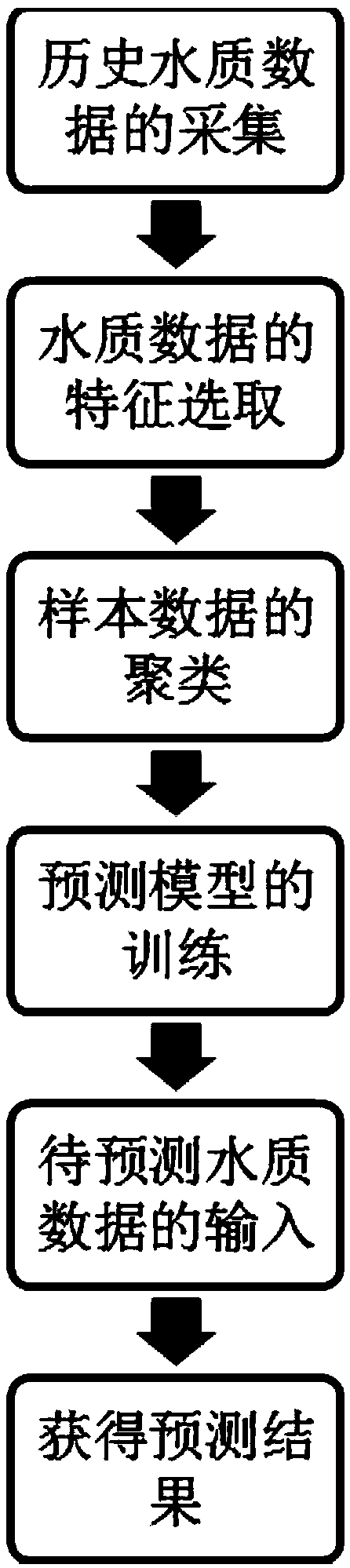
1.一种基于模糊聚类的支持向量回归算法的污水溶解氧浓度预测方法,其特征在于包括以下步骤:
S1.历史水质数据的采集,获取包含若干水质指标的历史水质时间序列数据;
S2.水质数据的特征选取,通过相关性分析,对获取的历史水质时间序列数据样本进行相关性分析,从而选取与溶解氧浓度较密切的若干指标;
S3.样本数据的聚类,利用模糊C均值聚类算法将样本数据分成C个子类样本;
S4.预测模型的训练,利用C个子类样本的水质特征矩阵对支持向量回归模型进行训练;
S5.待预测水质数据的输入,将待预测的污水数据通过聚类分为C类后,分别输入预测模型中;
S6.获得预测结果。
2.根据权利要求1所述的一种基于模糊聚类的支持向量回归算法的污水溶解氧浓度预测方法,其特征在于:上述S1步骤中获取的历史水质时间序列数据为水质的pH,MLSS,ORP,进水NH4N,出水COD,出水TP,进水累计流量,出水累计流量。
3.根据权利要求1所述的一种基于模糊聚类的支持向量回归算法的污水溶解氧浓度预测方法,其特征在于:上述S2步骤中水质数据的特征选取包括以下步骤:
根据获得的历史水质时间序列数据,建立以若干水质指标为特征的矩阵;
将t-1时刻的水质指标作为输入数据,t时刻的溶解氧浓度作为输出数据,计算相关性,其计算公式如下:
式中,x为t-1时刻的各水质指标,y为t时刻的DO浓度;R(X,Y)为相关系数,|R|的数值越大,表示变量x与y之间的关系越密切;
选取与DO浓度相关性较大的水质指标数据作为聚类样本的数据,建立特征矩阵存入内存;
所述样本数据的聚类包括以下步骤:
随机选取数据中的C个样本作为聚类中心,分别计算每个样本到聚类中心的距离,用dij=||xj-vi||表示;其中i和j分别用来表示样本数量和样本指标;
更新每个样本的隶属度矩阵,其计算公式如下:
更新聚类中心,其计算公式如下:
重新计算距离矩阵,并计算目标函数,直到满足迭代次数或者前后两次目标函数的绝对值之差小于迭代停止误差算法停止;目标函数式如下:
得到C个子类的样本数据。
4.根据权利要求1所述的一种基于模糊聚类的支持向量回归算法的污水溶解氧浓度预测方法,其特征在于:上述S4步骤中所述预测模型的训练包括以下步骤:
每一类样本进行标准化处理,其标准化的公式如式下:
式中,x是训练样本,mean(x),std(x)分别是训练的样本的均值和标准差;
分别把每个类别的数据样本按8:2的比例划分成训练数据和测试数据,选用RBF函数作为SVR模型的核函数,公式如下:
通过交叉验证分别选择C个类别的训练数据的惩罚系数V和核函数参数gamma的最佳超参数;
交叉验证原理是将数据集随机分组k组,每次将其中一个组作为测试数据,剩余的k-1组作为训练数据;
采用获得的最佳超参数对C个类别的训练数据进行训练,从而获取不同的支持向量回归模型,用测试样本对建立好的模型进行预测验证。
说明书
基于模糊聚类的支持向量回归算法的污水溶解氧浓度预测方法
技术领域:
本发明设计涉及大数据分析技术领域,具体说是一种基于模糊聚类支持向量回归的污水溶解氧浓度预测方法。
背景技术:
随着水资源的日益紧缩和水环境的污染的愈加严重,污水处理的问题越来越受到人们的关注。溶解氧DO是评价水质的的重要指标之一,但是目前存在的DO预测方法训练样本量小,没有考虑进水参数的测量存在滞后性,没有考虑时间参数,模型泛化能力不强,对于海量数据会出现欠拟合现象,导致预测准确率不佳。因此单纯的通过传感器的方法并不适合实时监测,所以我们采用支持向量回归的方法来预测未来时刻的DO浓度值。但是由于数据量庞大,支持向量回归算法将耗费大量的数据存储空间和运行时间,不利于在线实时监测。
因此本申请提出了基于模糊聚类的支持向量回归(FCM-SVR)算法来缩减样本数量,在不降低预测精度的同时,大幅度降低算法运算时间,从而实现在线预测。
发明内容:
本发明的目的是为了解决传统预测方法对污水中溶解氧DO的含量进行在线预测过程中存在计算复杂度高、时间复杂度高、预测精度不佳等缺陷,并提供一种基于模糊聚类支持向量回归的污水溶解氧浓度预测方法。
本发明所要解决的技术问题采用以下的技术方案来实现:
一种基于模糊聚类的支持向量回归算法的污水溶解氧浓度预测方法,包括以下步骤:
S1.历史水质数据的采集,获取包含若干水质指标的历史水质时间序列数据,这些指标例如水质的pH,MLSS,ORP,进水NH4N,出水COD,出水TP,进水累计流量,出水累计流量等;
S2.水质数据的特征选取,通过相关性分析,对获取的水质数据样本进行相关性分析,从而选取与溶解氧浓度较密切的若干指标;
S3.样本数据的聚类,利用模糊C均值聚类算法将样本数据分成C个子类样本;
S4.预测模型的训练,利用C个子类样本的水质特征矩阵对支持向量回归模型进行训练;
S5.待预测水质数据的输入,将待预测的污水数据通过聚类分为C类后,分别输入预测模型中;
S6.获得预测结果。
所述水质数据的特征选取包括以下步骤:
根据获得的历史水质时间序列数据,建立以若干水质指标为特征的矩阵;
将t-1时刻的水质指标作为输入数据,t时刻的溶解氧浓度作为输出数据,计算相关性,其计算公式如下:
式中,x为t-1时刻的各水质指标,y为t时刻的DO浓度;R(X,Y)为相关系数,|R|的数值越大,表示变量x与y之间的关系越密切;
选取与DO浓度相关性较大的水质指标数据作为聚类样本的数据,建立特征矩阵存入内存;
所述样本数据的聚类包括以下步骤:
随机选取数据中的C个样本作为聚类中心,分别计算每个样本到聚类中心的距离,用dij=||xj-vi||表示;其中i和j分别用来表示样本数量和样本指标;
更新每个样本的隶属度矩阵,其计算公式如下:
更新聚类中心,其计算公式如下:
重新计算距离矩阵,并计算目标函数,直到满足迭代次数或者前后两次目标函数的绝对值之差小于迭代停止误差算法停止;目标函数式如下:
得到C个子类的样本数据。
所述预测模型的训练包括以下步骤:
每一类样本进行标准化处理,其标准化的公式如式下:
式中,x是训练样本,mean(x),std(x)分别是训练的样本的均值和标准差;
分别把每个类别的数据样本按8:2的比例划分成训练数据和测试数据,选用RBF函数作为SVR模型的核函数,公式如下:
通过交叉验证分别选择C个类别的训练数据的惩罚系数V和核函数参数gamma的最佳超参数;交叉验证原理是将数据集随机分组k组,每次将其中一个组作为测试数据,剩余的k-1组作为训练数据;采用获得的最佳超参数对C个类别的训练数据进行训练,从而获取不同的支持向量回归模型,用测试样本对建立好的模型进行预测验证。
本发明的有益效果是:本发明所述的基于模糊聚类支持向量回归的污水溶解氧浓度预测方法,通过对数据样本做模糊聚类在不改变样本特征的情况下可以很好的降低数据样本的数量,由于模糊聚类是通过样本自身特征进行分类,很好的保留了时间序列的历史特征信息,有效的缩减了建模和预测数据的规模,能在保证算法预测精度上同时降低时间复杂度,然后再采取SVR算法对曝气过程进行建模,不仅可以确保模型的精度,而且可以在一定程度上缩小数据量,在保证模型精度的前提下,提高模型的预测效率。FCM-SVR模型训练数据建模时间较短,和SVR模型相比具有较好的综合性能,能够满足污水水质预测的实际需求。





